 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIteris: Agentic Research Loops for Computational Mathematics
Jun 01, 2026Recent advances in large language models and agentic AI systems have enabled significant progress in mathematical discovery, from solving competition problems to tackling research-level conjectures. However, open problems in computational mathematics have received comparatively less attention: research in this area often requires not only proofs but also numerical experimentation, adversarial constructions, and algorithm design. In this paper, we introduce an agentic research system, Iteris, designed for open problems in computational mathematics. We apply Iteris to two open problems from a recent Simons Workshop collection (arXiv:2602.05394). In these case studies, Iteris generated numerical evidence, constructions, and proof drafts that led, after expert review and correction, to verified results. The first result is a phase diagram for the asymptotic comparison between conjugate gradient and randomized coordinate descent on power-law spectra; the second is a counterexample showing that QR factorization with column pivoting can fail to select well-conditioned submatrices even under low coherence. These case studies suggest that agentic AI systems can participate meaningfully in research workflows for open problems in computational mathematics, while human validation remains essential.
Qwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
May 27, 2026Text-to-Image generation has evolved from basic image synthesis into a frequently used core capability in professional creative workflows, where simple text-image alignment can no longer satisfy users' pressing demands for faithful real-world reconstruction and genuine creative expression. Existing benchmarks, however, remain anchored in these foundational criteria and do not yet capture the nuanced capabilities that matter in authentic artistic practice, making it difficult to reliably distinguish state-of-the-art T2I models. To address the gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. Qwen-Image-Bench enriches conventional evaluation with two application-driven dimensions: Real-world Fidelity and Creative Generation. Drawing on the staged reasoning inherent in professional artistic workflows, we organize these five pillars into a top-down hierarchical taxonomy that further decomposes into 23 second-level sub-capabilities and 56 third-level verifiable rubrics. To ensure broad coverage, we curate 1000 stratified prompts with each prompt jointly exercising more than four fine-grained facets across multiple pillars. We train a unified judge model Q-Judger based on Qwen3.6-27B, supervised by 80 professional annotators from global art academies under blind labeling and triple-review protocols, that scores every image across all 56 verifiable facets, producing fine-grained, rubric-grounded, and fully attributable diagnostics rather than a single opaque score. Empirically, Qwen-Image-Bench reliably distinguishes leading T2I models, achieving the greatest separation on the two application-driven dimensions of Real-world Fidelity and Creative Generation where existing benchmarks provide little insight, while also providing a trustworthy optimization signal for production-level T2I development.
Qwen-Image-VAE-2.0 Technical Report
May 13, 2026We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
MUSE: Multi-Domain Chinese User Simulation via Self-Evolving Profiles and Rubric-Guided Alignment
Apr 15, 2026User simulators are essential for the scalable training and evaluation of interactive AI systems. However, existing approaches often rely on shallow user profiling, struggle to maintain persona consistency over long interactions, and are largely limited to English or single-domain settings. We present MUSE, a multi-domain Chinese user simulation framework designed to generate human-like, controllable, and behaviorally consistent responses. First, we propose Iterative Profile Self-Evolution (IPSE), which gradually optimizes user profiles by comparing and reasoning discrepancies between simulated trajectories and real dialogue behaviors. We then apply Role-Reversal Supervised Fine-Tuning to improve local response realism and human-like expression. To enable fine-grained behavioral alignment, we further train a specialized rubric-based reward model and incorporate it into rubric-guided multi-turn reinforcement learning, which optimizes the simulator at the dialogue level and enhances long-horizon behavioral consistency. Experiments show that MUSE consistently outperforms strong baselines in both utterance-level and session-level evaluations, generating responses that are more realistic, coherent, and persona-consistent over extended interactions.
ESOM: Efficiently Understanding Streaming Video Anomalies with Open-world Dynamic Definitions
Apr 09, 2026Open-world video anomaly detection (OWVAD) aims to detect and explain abnormal events under different anomaly definitions, which is important for applications such as intelligent surveillance and live-streaming content moderation. Recent MLLM-based methods have shown promising open-world generalization, but still suffer from three major limitations: inefficiency for practical deployment, lack of streaming processing adaptation, and limited support for dynamic anomaly definitions in both modeling and evaluation. To address these issues, this paper proposes ESOM, an efficient streaming OWVAD model that operates in a training-free manner. ESOM includes a Definition Normalization module to structure user prompts for reducing hallucination, an Inter-frame-matched Intra-frame Token Merging module to compress redundant visual tokens, a Hybrid Streaming Memory module for efficient causal inference, and a Probabilistic Scoring module that converts interval-level textual outputs into frame-level anomaly scores. In addition, this paper introduces OpenDef-Bench, a new benchmark with clean surveillance videos and diverse natural anomaly definitions for evaluating performance under varying conditions. Extensive experiments show that ESOM achieves real-time efficiency on a single GPU and state-of-the-art performance in anomaly temporal localization, classification, and description generation. The code and benchmark will be released at https://github.com/Kamino666/ESOM_OpenDef-Bench.
Learning Smooth and Robust Space Robotic Manipulation of Dynamic Target via Inter-frame Correlation
Mar 29, 2026On-orbit servicing represents a critical frontier in future aerospace engineering, with the manipulation of dynamic non-cooperative targets serving as a key technology. In microgravity environments, objects are typically free-floating, lacking the support and frictional constraints found on Earth, which significantly escalates the complexity of tasks involving space robotic manipulation. Conventional planning and control-based methods are primarily limited to known, static scenarios and lack real-time responsiveness. To achieve precise robotic manipulation of dynamic targets in unknown and unstructured space environments, this letter proposes a data-driven space robotic manipulation approach that integrates historical temporal information and inter-frame correlation mechanisms. By exploiting the temporal correlation between historical and current frames, the system can effectively capture motion features within the scene, thereby producing stable and smooth manipulation trajectories for dynamic targets. To validate the effectiveness of the proposed method, we developed a ground-based experimental platform consisting of a PIPER X robotic arm and a dual-axis linear stage, which accurately simulates micro-gravity free-floating motion in a 2D plane.
TED: Training-Free Experience Distillation for Multimodal Reasoning
Mar 25, 2026Knowledge distillation is typically realized by transferring a teacher model's knowledge into a student's parameters through supervised or reinforcement-based optimization. While effective, such approaches require repeated parameter updates and large-scale training data, limiting their applicability in resource-constrained environments. In this work, we propose TED, a training-free, context-based distillation framework that shifts the update target of distillation from model parameters to an in-context experience injected into the student's prompt. For each input, the student generates multiple reasoning trajectories, while a teacher independently produces its own solution. The teacher then compares the student trajectories with its reasoning and the ground-truth answer, extracting generalized experiences that capture effective reasoning patterns. These experiences are continuously refined and updated over time. A key challenge of context-based distillation is unbounded experience growth and noise accumulation. TED addresses this with an experience compression mechanism that tracks usage statistics and selectively merges, rewrites, or removes low-utility experiences. Experiments on multimodal reasoning benchmarks MathVision and VisualPuzzles show that TED consistently improves performance. On MathVision, TED raises the performance of Qwen3-VL-8B from 0.627 to 0.702, and on VisualPuzzles from 0.517 to 0.561 with just 100 training samples. Under this low-data, no-update setting, TED achieves performance competitive with fully trained parameter-based distillation while reducing training cost by over 5x, demonstrating that meaningful knowledge transfer can be achieved through contextual experience.
RoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Mar 13, 2026Scalable Embodied AI faces fundamental constraints due to prohibitive costs and safety risks of real-world interaction. While Embodied World Models (EWMs) offer promise through imagined rollouts, existing approaches suffer from geometric hallucinations and lack unified optimization frameworks for practical policy improvement. We introduce RoboStereo, a symmetric dual-tower 4D world model that employs bidirectional cross-modal enhancement to ensure spatiotemporal geometric consistency and alleviate physics hallucinations. Building upon this high-fidelity 4D simulator, we present the first unified framework for world-model-based policy optimization: (1) Test-Time Policy Augmentation (TTPA) for pre-execution verification, (2) Imitative-Evolutionary Policy Learning (IEPL) leveraging visual perceptual rewards to learn from expert demonstrations, and (3) Open-Exploration Policy Learning (OEPL) enabling autonomous skill discovery and self-correction. Comprehensive experiments demonstrate RoboStereo achieves state-of-the-art generation quality, with our unified framework delivering >97% average relative improvement on fine-grained manipulation tasks.
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025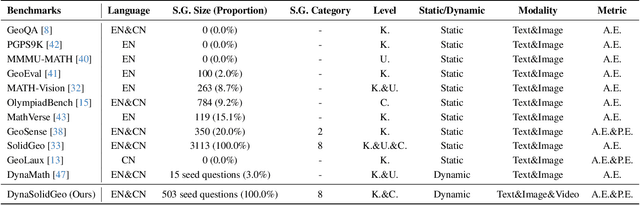

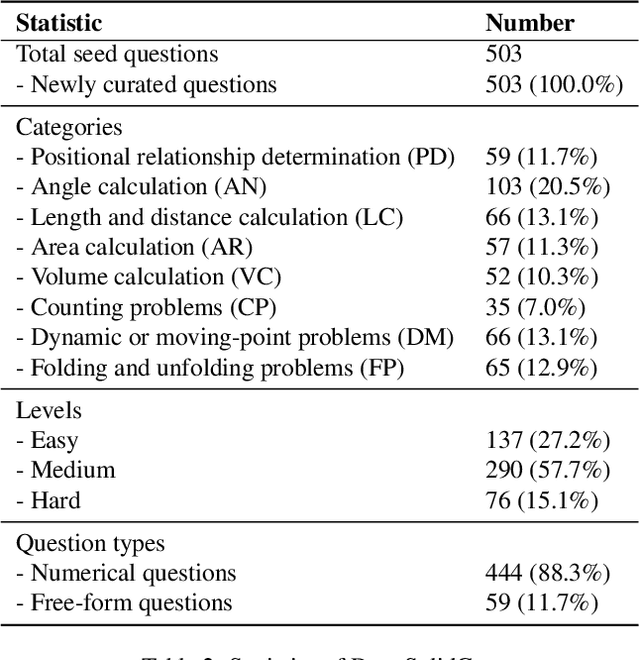

Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.